Unified multi-task encoder
One Swin-Transformer encoder trained jointly across depth, pose, 3D scene flow and four segmentation tasks — a single latent space that carries every cue a driver uses.
A single shared encoder trained jointly on depth, pose, 3D scene flow and four kinds of segmentation — then frozen, its latent space steers a car better than ImageNet pretraining. First-author paper with MIT CSAIL, accepted to ICRA 2026.
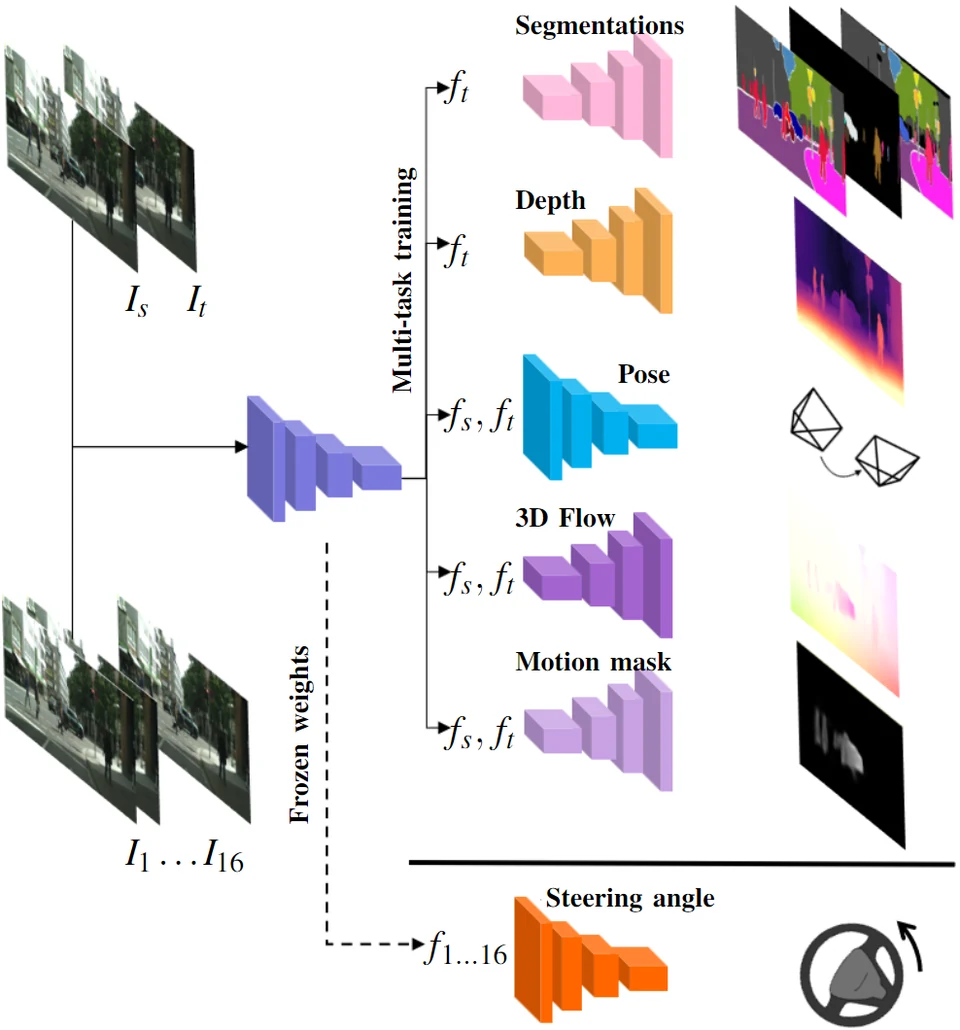
Estimating steering angle straight from a camera is starved of labelled data — train an encoder on that one task and it overfits. A human driver doesn't work that way: we read depth, motion, layout, and who's about to move, all at once. So we trained a single encoder to do the same thing.
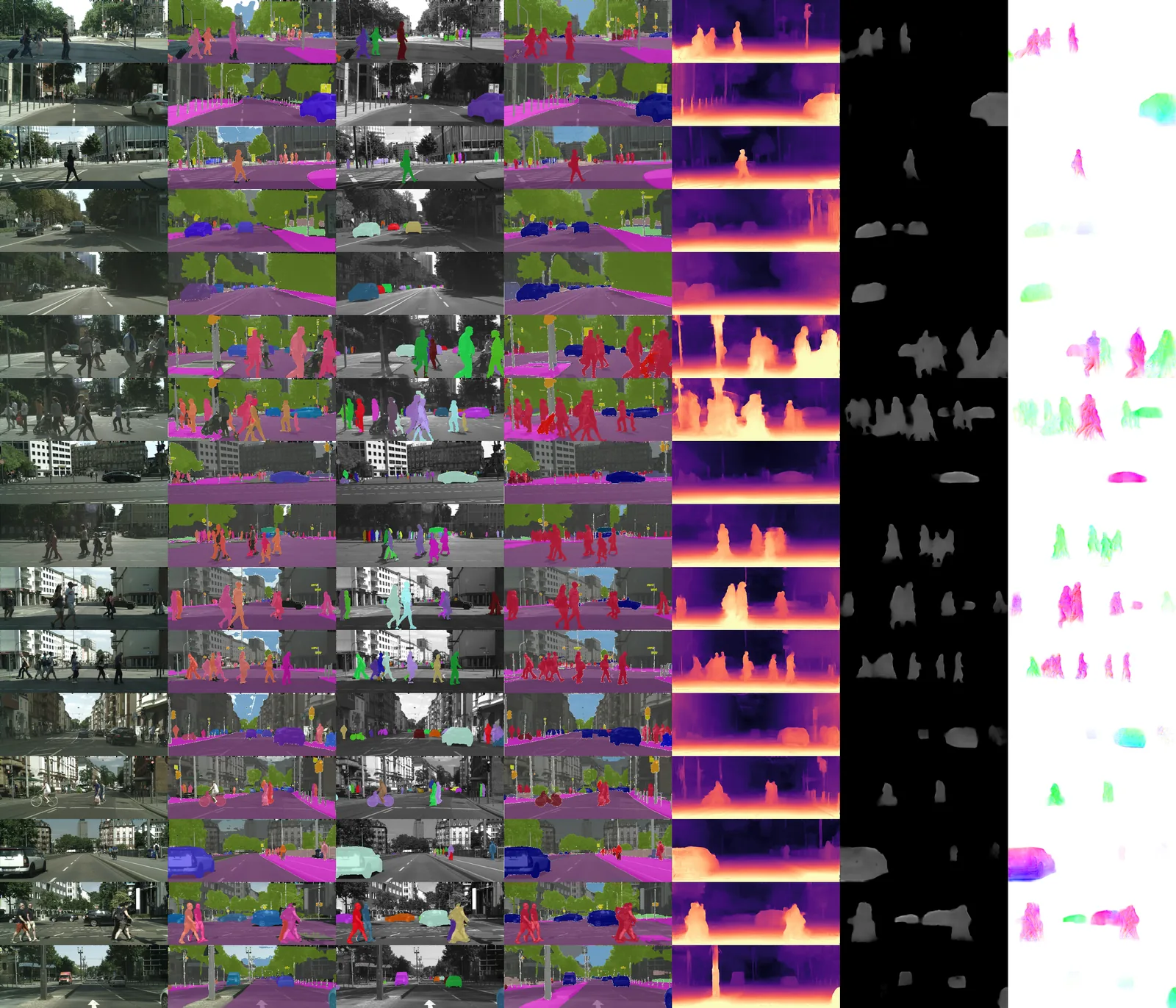
Together with MIT CSAIL (Wei Xiao, Tsun-Hsuan Wang, Ramin Hasani, Daniela Rus) and the Capgemini Engineering Hybrid Intelligence team, I built one Swin-Transformer encoder trained jointly on depth, camera pose, 3D scene flow, and semantic, instance, panoptic and motion segmentation. A multi-scale pose network sharpens the depth signal, and knowledge distillation from several pretrained backbones keeps the joint training stable.
The shared encoder holds its own against task-specific specialists — on par with OneFormer for panoptic segmentation and competitive on depth across KITTI and Cityscapes. The headline result: frozen, its latent space predicts steering more accurately than the same encoder fine-tuned, and than an ImageNet-pretrained one. The paper was accepted to ICRA 2026.
One Swin-Transformer encoder trained jointly across depth, pose, 3D scene flow and four segmentation tasks — a single latent space that carries every cue a driver uses.
A pose branch that reads features at several scales, which in turn sharpens the self-supervised depth the rest of the system depends on.
Knowledge distilled from several pretrained backbones to anchor and stabilise the joint training, so no single task collapses the shared representation.
Left frozen, the encoder's dense representation predicts steering angle better than its own fine-tuned version and than ImageNet pretraining — the transfer result at the heart of the paper.